A process of Reinforcement Learning wherein outputs are given human feedback for tailored reasoning.
- Doesn’t change what the model is, just teaches it what not to say
Similar to an ELO Rating System
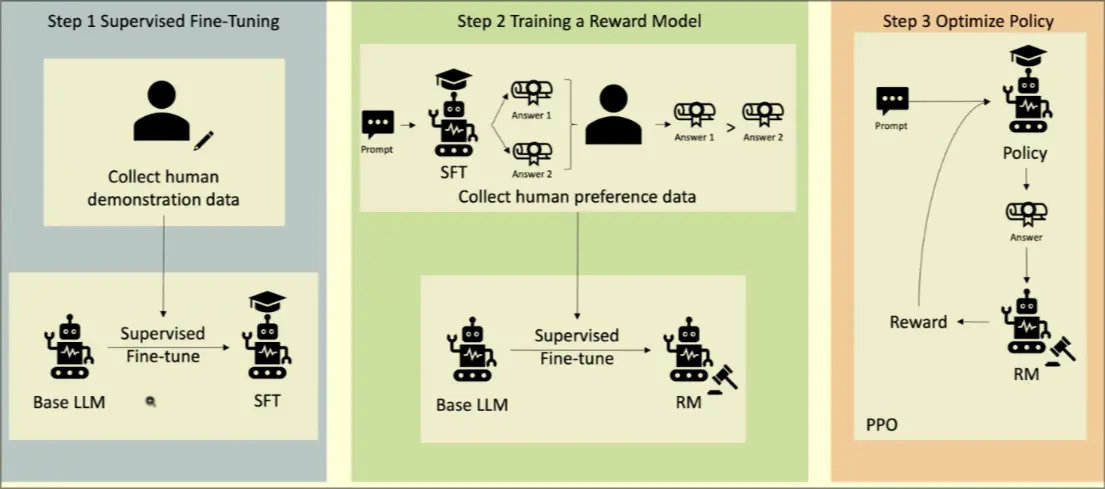
- Step 1: Human collected data to describe how the AI should behave. Human demonstrated data is harmful vs harmful data pairs
- Step 2: SFT model creates a judge RM model
- Step 3: Optimize policy with PPO
RL
Process
- Human given prompt → outputs. Ranks each output against each other.
- Create a values coach from these responses, a small LM that checks if responses cohere with our indicated values
- Create a coherence coach, a copy of the model that is used to check if responses are coherent
- Model is given reward by a combination of values coach and coherence coach rewards