A method that involves attached Transcoder to Transformer layers to view intermediate results of a neural network.
Method
- Use a CLT or a a SAE to remove Polysemanticity for a local prompt (model will have to change for different prompts)
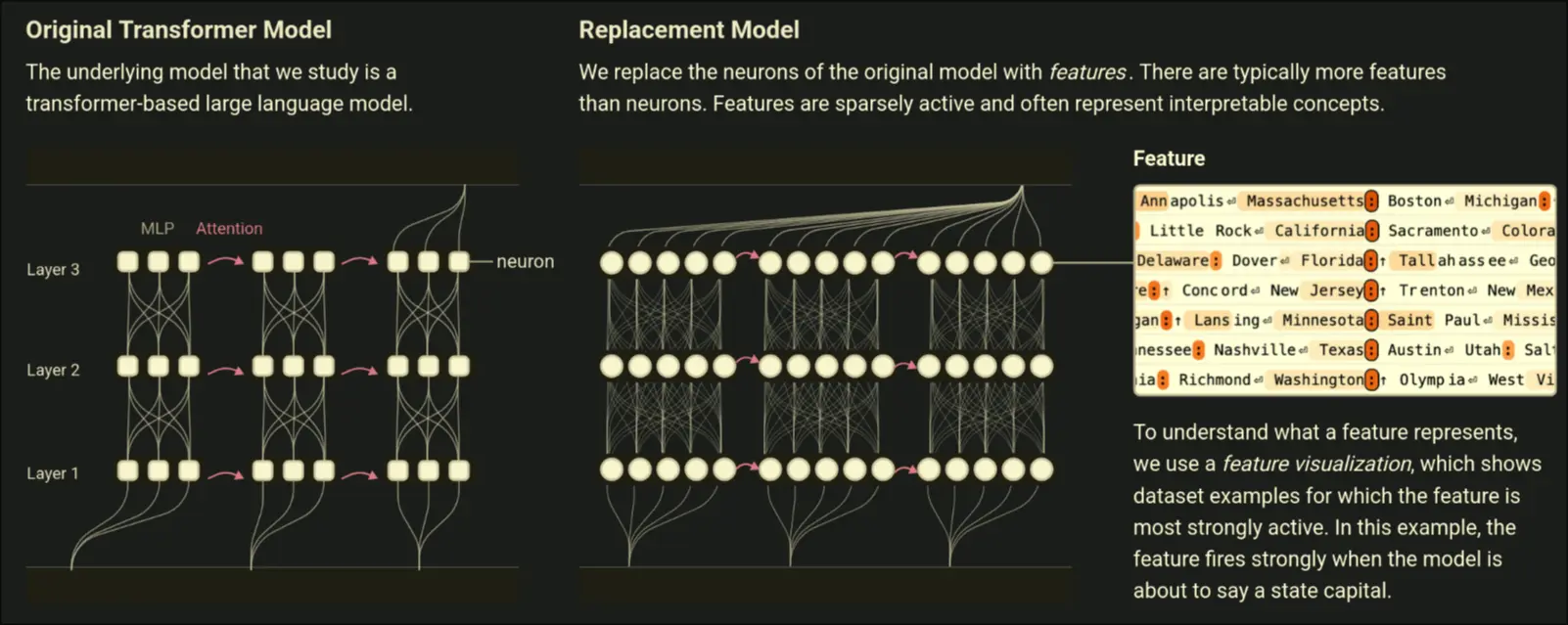
- Error nodes represent discrepancy between two models, but we cant interpret error nodes
- Create an attribution graph comprised of:
- Nodes being the active features, Embeddings from the prompt, errors and output Logit
- Edges being the linear effects between nodes, activity of each features is the sum of its input edges
- Use Transcoder to achieve linear attribution between features
- Prune the attribution graph to most important components by removing nodes and edges not contributing to model output
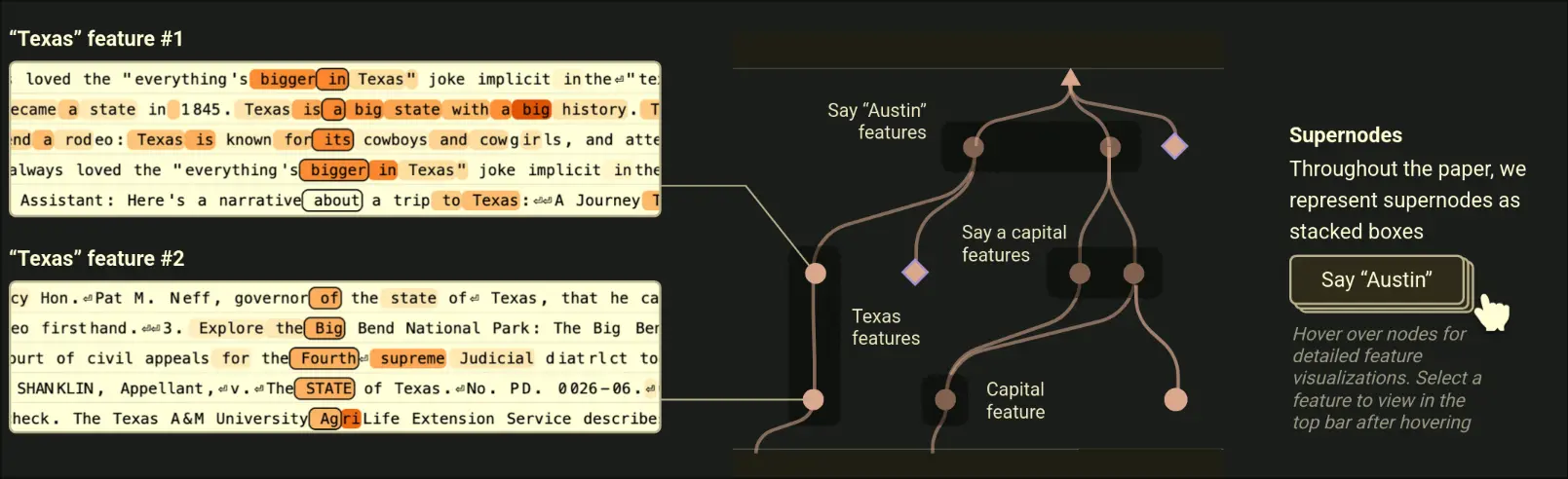
- Group related nodes (nodes with similar meaning) into super-nodes