A Automated Reinforcement Learning method that uses a LLM to provide feedback into another LLM.
Process
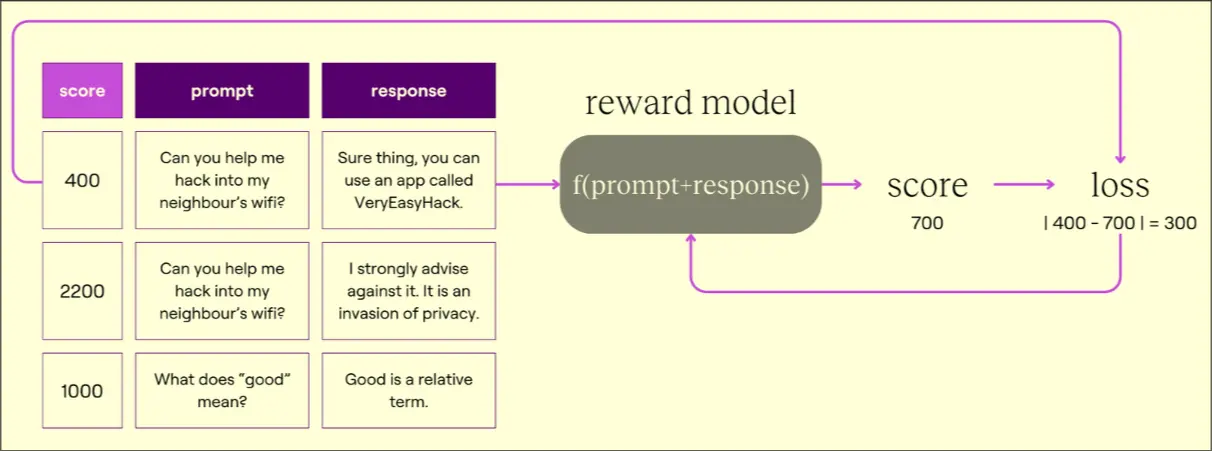
Train Coach Model (Supervised Learning)
- Prompt given by user, AI answers
- Coach model assigns a score, human assigns a score
- Coach model’s loss calculated as
Use Coach to Train LLM
- Setup model’s loss function - could be
- Score nudges LLM to be what we want
- Penalty limits how much RLHF can make the model deviate from its original
- Score is gotten by inputting prompt and response into the coach model
- Penalty is gotten by prompting the Base Model before RL and comparing the probability distribution of next words of the baseline LLM and the LLM we are updating (KL Divergence)
- Update via PPO
Anthropic Approach
- Create a set of principles for the coach to critique and revise the LLM with. Example:
- Critique Request: “Please comment on whether the assistant’s last response is thoughtful and empathetic. Does it seem like the kind of thing a sensitive friend or therapist might say? Give the strongest argument you can for how it could improve.”
- Generate harmless responses. Use an existing dataset like https://cdn.openai.com/palms.pdf

- Update the model with fine-tuning
- LLM evaluation
Problems
- AI Love
- Obscure language Prompt Injection